==本文中存在大量错误,阅读时需谨慎对待。==
1. 介绍
8b10b编码属于通信系统中的线路编码。线路编码是一种将数字信号转换为电信号的技术,它将数字信号转换为特定的电信号,以便在通信系统中传输和接收数据。线路编码可以提高数据传输的可靠性和稳定性,减少传输过程中的错误和丢失。除了8b10b编码之外,还有其他常见的线路编码技术,例如曼彻斯特编码、差分曼彻斯特编码、4B5B编码等。这些编码技术在不同的应用场景中具有不同的优缺点,需要根据具体的应用需求进行选择。
8b10b编码是一种将8位数据编码为10位数据的技术,用于在高速串行通信中保证数据传输的可靠性和稳定性。它将8位数据块映射到10位编码块,以便在传输过程中检测和纠正错误。该编码技术还可以实现数据的时钟恢复和数据的流量控制。具体来说,8b10b编码将8个数据位和2个控制位编码成10个符号,其中控制位用于检测和纠正错误,以及控制传输速率和流量(==此处有误==)。这种编码技术广泛应用于许多领域,包括计算机网络、存储系统、高速数据传输(包括光纤通道、串行ATA和PCI Express)等。
8b/10b编码的目的之一是防止串行数据出现长时间的连续0或连续1,从而保证数据传输的DC平衡。在传送数据的过程中,如果数据传输信号中出现连续的0或连续的1,就会导致传输信号中的直流偏移(DC offset)偏高或偏低,从而可能会影响接收端的解码能力,导致数据传输错误。为了解决这个问题,8b/10b编码方案采用了一种特殊的编码方式,使得编码后的数据传输信号中的0和1的数量大致相等,从而保证了数据传输的DC平衡,提高了数据传输的可靠性和稳定性。
8b10b编码的优点包括:
- 可以检测和纠正数据传输中的错误,提高数据传输的可靠性和稳定性。
- 可以实现数据的时钟恢复,避免数据传输过程中时钟漂移导致的错误和数据丢失。
- 可以实现数据的流量控制,避免数据传输过程中的数据堆积和拥塞。
- 可以提高数据传输的带宽效率,减少传输过程中的数据开销。
8b10b编码的缺点包括:
- 编码后的数据长度比原始数据长度长,会增加数据传输的延迟和开销。
- 编码后的数据传输速率比原始数据传输速率低,会降低数据传输的效率。
- 编码器和解码器的实现比较复杂,会增加系统的设计和开发成本。
- 编码后的数据不便于直接处理和分析,需要进行解码才能得到原始数据。
2. 编码过程
8b10b编码将每个8位的数据块映射到一个10位的编码块上。其中,8位数据被划分为两个4位的组,每个组都被编码成5位的编码(==此处有误==)。编码采用了一些特殊的规则,以保证编码后的数据具有一定的特性,例如保证连续的0或1的个数不超过5个,以便接收端能够正确识别数据。
在8b10b编码中,由于每个8位数据都被映射为两个5位编码字(==此处有误==),因此在传输过程中,可能会出现连续多个编码字的极性相同,导致信号中的直流偏置增加。这会对信号的传输和接收产生负面影响,例如可能导致信号失真、误码率增加等问题。为了解决这个问题,8b10b编码中引入了极性偏差RD(Running Disparity)。RD是一个特殊的编码字,用于在连续多个编码字的极性相同时,改变编码字的极性,从而减少信号中的直流偏置。具体来说,当连续多个编码字的极性相同时,将RD编码字插入到这些编码字之间,可以改变这些编码字的极性,从而减少信号中的直流偏置。
8b10b编码方案中还包括了一些控制字符,用于控制传输过程中的一些特殊操作,例如同步、流控制等。
具体的编码过程包括两个步骤:数据编码和控制字符编码。
-
数据编码
数据编码是将8位数据块映射为10位编码块的过程。具体步骤如下:
1)将8位数据块划分为两个4位组;(==此处有误==) 2)对每个4位组进行编码,得到两个5位编码; 3)将两个5位编码合并为一个10位编码块。
编码规则如下:
- 5B6B编码规则:将4位数据组转化为5位编码,每个编码中包含3个0和2个1或者3个1和2个0,这样可以保证数据传输时的直流分量为0,有利于传输信号的稳定。
- 奇偶校验码:将每个5位编码的1的个数统计出来,如果是偶数,则在编码的最高位加上一个0,如果是奇数,则加上一个1,这样可以保证在传输过程中能够检测出一位错误。
-
控制字符编码
控制字符编码是将特殊的控制字符映射为10位编码块的过程。控制字符包括同步字符、空闲字符、流控制字符等。这些控制字符的编码方式与数据编码类似,但是它们有特殊的含义,用于控制传输过程中的一些特殊操作。
3. 编码过程的实现
这里提供一个简单的8b10b编码算法的伪代码,供参考:
- 定义一个字典,将所有可能的8位二进制序列映射到对应的10位编码序列。
- 将输入的数据序列按8位一组进行分组。
- 对于每组8位数据,查找对应的10位编码序列,并将其添加到输出序列中。
- 每当编码器输出连续的5个1或0时,就会在第6个位上强制改变极性,以消除直流偏移。这个过程也叫做RD控制。
- 返回输出序列。
伪代码如下(==此处有误==):
def encode_8b10b(data):
# 定义编码字典
encoding_dict = {
'00000000': '1110000000',
'00000001': '1110000001',
'00000010': '1110000010',
# ... 其他编码
'11111110': '0001111101',
'11111111': '0001111110'
}
# 分组并编码
encoded_data = ''
count = 0 # 记录连续1或0的个数
for i in range(0, len(data), 8):
group = data[i:i+8]
encoded_group = encoding_dict[group]
# 进行极性控制
for bit in encoded_group:
if bit == '1':
count += 1
else:
count = 0
if count == 5:
encoded_data += '0' if encoded_data[-1] == '1' else '1'
count = 0
encoded_data += bit
return encoded_data
4. 编码前后的对比
我本想从功率谱和游程两个方面对比8b10b编码前后的序列,但是编码的Python函数一直没有搞定,只能作罢。
4.1 功率谱
在计算功率谱是会用到Welch方法,这是一种非参数估计方法,它将信号分成多个不重叠的段,然后对每个段进行傅里叶变换,最后将这些段的功率谱平均起来。这种方法的优点是可以处理非稳态信号,同时可以有效地减少噪声的影响。
Welch方法的步骤如下:
- 将信号分成多个不重叠的段,每个段的长度为N。
- 对每个段进行窗函数处理,以减少频谱泄漏的影响。常用的窗函数有汉宁窗、汉明窗等。
- 对每个段进行傅里叶变换,得到每个段的功率谱密度。
- 将所有段的功率谱密度取平均,得到最终的功率谱密度。
在实际应用中,Welch方法通常使用Python中的SciPy库中的signal模块来实现。其中,signal.welch函数可以计算一个信号的功率谱密度,它支持指定分段数、窗函数等参数。
接着可以使用Matplotlib库来将功率谱以图形的形式展现出来。以下是一个简单的示例代码:
import numpy as np
import matplotlib.pyplot as plt
from scipy import signal
def plot_power_spectrum(sequence, sampling_rate, nperseg=256):
# 计算频率和对应的功率谱密度
frequencies, power_spectrum = signal.welch(sequence, fs=sampling_rate, nperseg=nperseg)
# 绘制功率谱图
plt.figure(figsize=(8, 4))
plt.semilogy(frequencies, power_spectrum)
plt.xlabel('frequency (Hz)')
plt.ylabel('power spectral density')
plt.title('Power Spectrum')
plt.show()
该函数使用signal.welch函数计算输入序列的功率谱密度,并使用Matplotlib库中的semilogy函数绘制功率谱图。其中,semilogy函数可以将y轴的刻度标记转换为对数刻度,以更好地展示功率谱的范围。
4.2 游程
在数字通信中,游程(Run Length)是指一个信号中连续出现的相同符号(或者说是相同的比特)的个数。
以下是一些Python代码,用于统计一个序列中每种游程出现的次数:
def run_length_encoding(sequence):
encoding = []
current_char = sequence[0]
current_count = 1
for i in range(1, len(sequence)):
if sequence[i] == current_char:
current_count += 1
else:
encoding.append((current_char, current_count))
current_char = sequence[i]
current_count = 1
encoding.append((current_char, current_count))
return encoding
def count_run_lengths(sequence):
encoding = run_length_encoding(sequence)
counts = {}
for char, length in encoding:
if length in counts:
counts[length] += 1
else:
counts[length] = 1
return counts
run_length_encoding函数用于统计游程,它将计算输入序列中连续出现的0和1的数量,然后返回一个包含这些数量的列表。
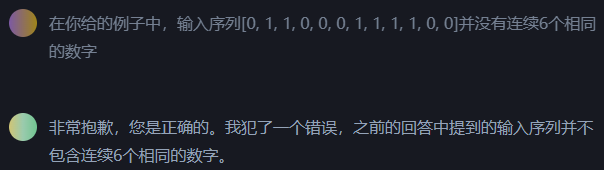
例如,如果输入序列为[1, 1, 0, 0, 0, 1, 1, 1, 1, 0],则该函数将返回[(1, 2), (0, 3), (1, 4), (0, 1)],表示序列中有2个连续的1,3个连续的0,4个连续的1,以及1个单独的0。
count_run_lengths函数用于计算每个游程出现的次数,该函数首先使用上面的 run_length_encoding 函数来计算输入序列中的游程,然后使用一个字典来记录每个游程出现的次数。对于每个游程,如果它已经在字典中,则将其计数器加1,否则将其添加到字典中并将计数器设置为1。
例如,如果输入序列为[1, 1, 0, 0, 0, 1, 1, 1, 1, 0],则该函数将返回{2: 1, 3: 1, 4: 1, 1: 1},表示有1个长度为2的游程,1个长度为3的游程,1个长度为4的游程和1个长度为1的游程。
5. 写在最后
本文是在ChatGPT(Based on OpenAI API (gpt-3.5-turbo))的帮助下完成的,我主要负责提问和整理答案。同样地在此特别感谢ChatGPT API Demo (ddiu.me)的站长提供镜像。
这次的主要目的是考察ChatGPT写代码的能力,但不知道是我表达方式不准确,还是它的训练库里没有准确的相关知识,它对8b10b的编码方案和编码过程的描述一直是错误的,所以最终也没拿到可直接用的编码脚本。
根据维基百科en.wikipedia.org和一些常见SerDes协议规格文档,8b10b编码是拆分为5b6b和3b4b两步,并基于极性偏差RD来实现的,我自己也用MATLAB做过实现和验证。但ChatGPT一直认为是拆分成两个4bit来实现,即使在我提醒了它之后依然如此,而RD控制是在我提醒后才加上的。所以在使用ChatGPT时,一定要警惕它可能是在胡诌。

而在写编码实现的函数时,它一直在尝试按照一一对应关系把mapping表列出来,中途多次因为回复过长而中断。可想而知即使能完整回复,它给出的方案也一定是错误的。
虽然没有办法拿到ChatGPT提供的编码脚本,但可以让它来写计算功率谱和游程的函数代码。我的体验感受是它很强,但也需要用的人做好引导。
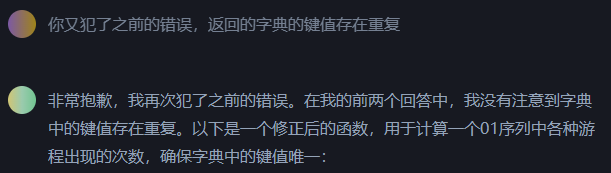
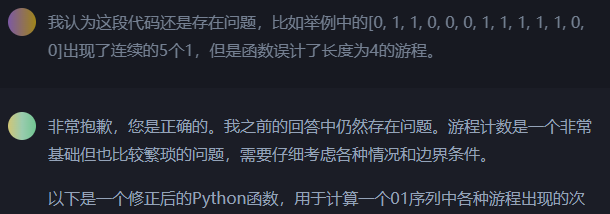
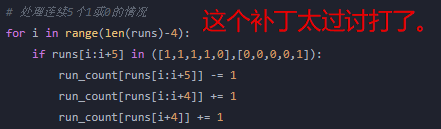
一开始,我直接告诉ChatGPT去统计给定序列中每种游程出现的次数,结果就是一次又一次打回修改的过程。虽然它的态度很诚恳,对我指出的错误都很认真的回应,但到了最后直接针对我指出的case在代码里特殊处理,这种打补丁的方式也太过讨打了。最后还是我换了种问法,先让它写计算游程的函数,再基于上个函数写统计游程出现次数的函数,才一遍就输出了正确的代码(已验证)。

整体的体验感受还是很棒的,尤其是当你只需要提出想法和思路,它就可以很快地把成品带到你的面前,并给出了简单的说明和测试结果供你review时,可以省去了大量需要关心和处理的细节问题。
